Archive Data
Background
As a high throughput blockchain with frequent blocks, Monad generates a lot of data - both transactional data (blocks, transactions, receipts, logs, and traces), and state data (the full state trie at the end of each block).
Full nodes and validators store as much of this data as possible in MonadDB, overwriting the oldest data when the storage capacity hits 80%. If an RPC call requests data older than whatever is locally available, the node must reference an external source. This is where Archive Servers come in.
Archive Servers
An Archive Server is a standalone server that stores historical transactional data. Note that Archive Servers don't store state data - see here for a discussion why.
An Archive Server is fed this data by a separate full node running an additional process called the Archive Writer.
Archive Servers serve requests for historical transactional data that is no longer available (due to pruning) on the requestor node. Note that many full nodes and validators can point to the same Archive Server.
Databases
MonadDB (TrieDB)
MonadDB, also called TrieDB, is a local state database run by each full node and validator. It maintains the most recent state tries, as well as the corresponding transactional data.
Once the storage capacity of MonadDB reaches 80%, the node begins overwriting the oldest data. Because of this mechanism, and because of frequent blocks and high chain throughput, most MonadDB instances don't store the entire blockchain history.
ArchiveDB (MongoDB)
ArchiveDB is a MongoDB database that runs on an Archive Server. It is fed by an Archive Writer process on a Full Node.
Full nodes and validators can be configured to use ArchiveDB as a source of historical data when that data is unavailable in their local MonadDB.
Object Storage
As an alternative to MongoDB, archive data can be stored in an object storage service (e.g., AWS S3).
While MongoDB is preferred for performance and query efficiency, object storage provides a viable fallback option for users who prefer off-site or cloud-based data retention.
Like ArchiveDB, the object storage can also be configured in the RPC client as a source of historical data.
Data Access Order
When the RPC client retrieves data, it follows this priority order:
- Chain State Buffer (in-memory cache)
- MonadDB (TrieDB)
- ArchiveDB (MongoDB)
- Object Storage
ArchiveDB is given preference over Object Storage if both are configured. Configuring both is recommended to ensure that there is a fallback mechanism in case of any issues with the ArchiveDB instance.
Architecture
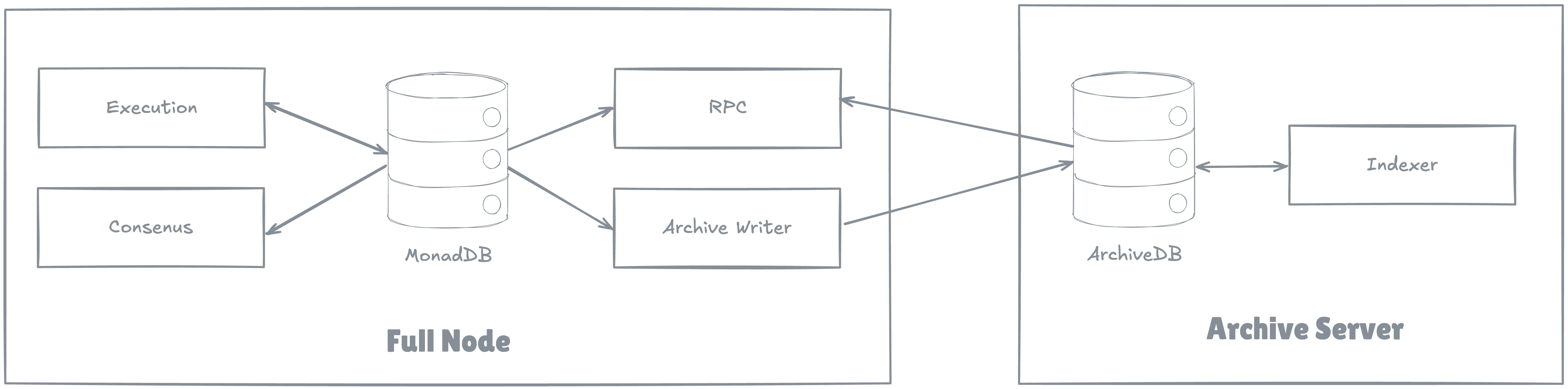
Monad Archive Server architecture
Stored Data
ArchiveDB stores the following data types:
- blocks
- transactions
- receipts
- logs
- traces
For more details about historical data, see the Historical Data page.